در این مقاله به معماریها Sharding و sharding- new-features19 c خواهیم پرداخت. در مقاله قبلی به معرفی sharding و انواع پارتیشنبندیهای آن و بررسی مزایا و معایب آن پرداختیم.
یادآوری مزایای استفاده از sharding

Oracle Sharding بخشهایی از یک مجموعه داده را در بسیاری از پایگاههای داده (شاردها) در رایانههای مختلف، در محل یا در cloud توزیع میکند و در صورت بروز مشکل برای یک shard ما همه دیتابیس را از دست نمیدهیم و همچنین بیان شد که امکان توسعه آنلاین شاردها را داشتیم.
آشنایی با معماریهای Sharding
حال فرض کنیم که بسته به نیازهای بیزینس آنلاین خود، نیاز به پارتیشنبندی دیتابیس خود داریم، اما اکنون سوال اینجا است که برای شروع دست به چه کاری باید بزنیم؟ به عنوان یک قانون کلی، باید این نکته را مد نظر داشته باشیم که وقتی قصد داریم به چندین دیتابیس یا جدول مختلف کوئری بزنیم، نیاز است تا دقیقاً بدانیم که کوئری مد نظرمان برای پارتیشن/ شارد/ جدول درستی ارسال میشود که در غیر این صورت با نتایجی اشتباه و گاهی هم از دست دادن دیتا مواجه خواهیم شد. در همین راستا، در ادامه به معرفی برخی معماریهای رایج Sharding میپردازیم که هر کدام از آنها از رویکرد مختلفی به منظور پخش کردن دادهها در میان پارتیشنهای مختلف استفاده میکند.
Key Based Sharding: در این نوع معماری وقتی که دیتای جدیدی در دیتابیس ثبت میگردد، کلیدی مرتبط با آن دیتا در نظر گرفته میشود (به طور مثال، اگر یک مشتری جدید در فروشگاه آنلاینی ثبتنام میکند، customer_id به عنوان چنین کلیدی در نظر گرفته خواهد شد) سپس این کلید به فانکشنی داده میشود که بسته به ورودیای که میگیرد، مشخص میکند که آن دیتا روی چه پارتیشنی باید ذخیره گردد به طوری که داریم:
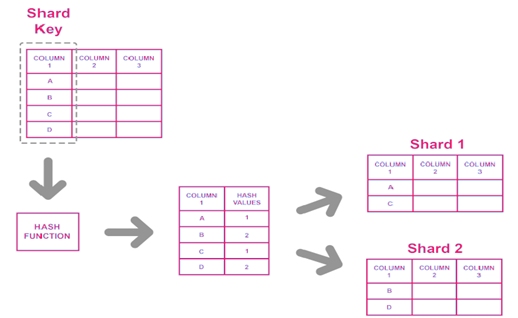
به منظور اطمینان حاصل کردن از اینکه دادهها به درستی در پارتیشنهای مناسبی ذخیره میگردند، نیاز است تا مقادیر، که وارد چنین فانکشنی میشوند که تحت عنوان Hash Function شناخته میگردد، منحصربهفرد باشند. برای درک بهتر این موضوع، میتوان Primary Key را به عنوان چنین دیتایی در نظر گرفت که در این معماری چنین کلیدی تحت عنوان Shard Key شناخته میشود و نیاز به توضیح نیست که این کلید هرگز نباید در طول زمان دستخوش تغییر شود که در غیر این صورت، یکپارچگی دادهها به هم خواهد خورد و اگر هم اینطور نشود، پردازش زیادی برای آپدیت پارتیشنهای مربوطه نیاز خواهد بود.
یکی از چالشهای کار با معماری Key Based Sharding آن است که در صورت نیاز به افزودن سرورهای جدید و یا کم کردن تعداد سرورهای موجود، کار ممکن است به مشکل بخورد. بدین صورت که مثلاً وقتی سرور جدیدی به کلاستر خود اضافه میکنیم، هر سرور نیاز به اصطلاحاً یک Hash Value دارد تا در حین ثبت دادههای جدید مورد استفاده قرار گیرد اما این در صورتی است که اگر بخواهیم دادههای موجود را روی این سرور انتقال دهیم، نیاز به آپدیت دیتا به منظور شناخت این Hash Value داریم که این کار بسیار پرهزینه خواهد بود.
Range Based Sharding: همانطور که از نام این معماری مشخص است، در این روش دیتا را بر اساس بازهی خاصی روی پارتیشنهای مختلف پخش میکنیم. مثلاً فرض کنیم که در یک فروشگاه آنلاین دیتابیسی داریم که دادههای مرتبط با تمامی محصولات در آن ذخیره شده است. حال به منظور پارتیشنبندی چنین دیتابیسی میتوان از دیتابیسها یا جداول مختلفی بر اساس قیمت محصولات استفاده نماییم:
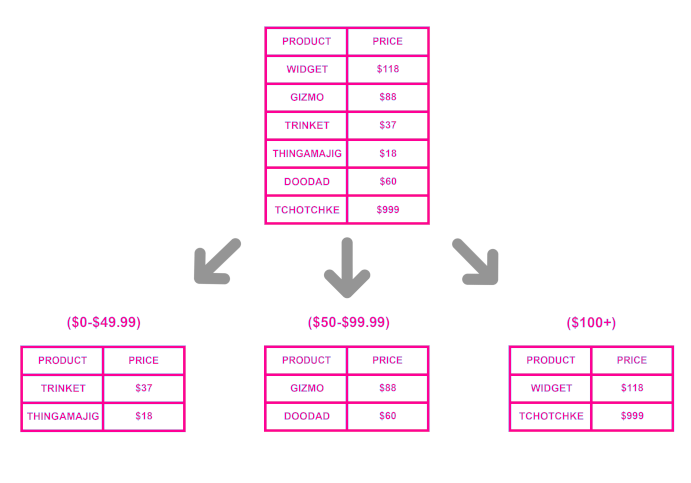
نیاز به توضیح نیست که یکی از مزایای پیادهسازی این معماری سادگی آن است به طوری که اِسکمای تمامی پارتیشنها یکسان است. در چنین شرایطی، وقتی هم که بخواهیم در سطح اپلیکیشن تصمیم بگیریم که دادهی جدید در کدام پارتیشن ذخیره شود، صرفاً نیاز است به بازهی قیمتی آن توجه کرد و بسته به آن قیمت پارتیشن مرتبط را انتخاب کرد. در عین حال، همچون مثالی که قبلاً در ارتباط با حروف الفبا زدیم، در این نوع معماری ممکن است تعادل بهم بخورد به طوری که مثلاً این احتمال وجود دارد محصولاتی که در بازهی 10/000 تا 100/000 تومان هستند بسیار زیاد باشند و بالطبع پارتیشن مرتبط با این بازه بسیار حجیم خواهد شد.
Directory Based Sharding: همانطور که در تصویر زیر مشاهده میکنید، در این معماری نیاز به یک اصطلاحاً Lookup Table داریم که این وظیفه را دارا است تا Shard Key، که قبلاً با مفهوماش آشنا شدیم، را در خود ذخیره سازد تا بر آن اساس مشخص شود که چه پارتیشنی چه نوع دیتایی را در خود ذخیره کرده است. به زبان عامیانه، این جدول همچون فهرست واژگان در انتهای برخی کتابها است که از آن طریق مشخص میشود کدام اصطلاح در کدام بخش یا کدام صفحه استفاده شده است. اگر بخواهیم این معماری را به صورت ساده تشریح کنیم، خواهیم داشت:
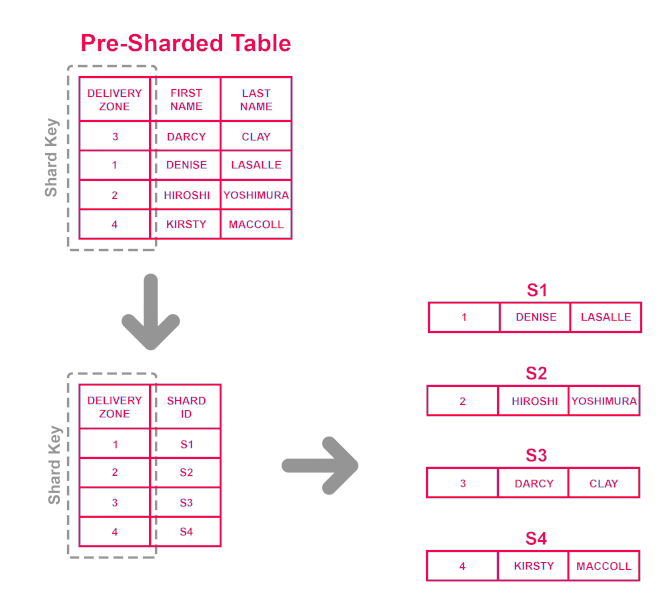
همانطور که در تصویر فوق مشخص است، ستون Delivery Zone به عنوان Shard Key در نظر گرفته شده است. سپس دادهها براساس این ستون در Lookup Table ثبت میشوند. بدین صورت که مشخص میشود هر کلید مرتبط با کدام پارتیشن است. در مقایسه با معماری قبلی (Range Based Sharding)، در مواقعی که مهم نباشد برای ذخیرهسازی دیتا از کدام پارتیشن استفاده شود، برگ برنده در دست Directory Based Sharding است.
یکی از مزایای قابلتوجه این نوع معماری آن است که انعطافپذیری بالایی دارا است. به طوری که دست دولوپر را باز میگذارد تا از الگوریتم اختصاصی خودش برای پخش کردن دیتا مابین پارتیشنهای مختلف استفاده کند مضاف بر اینکه افزودن پارتیشنهای جدید به صورت دینامیک نیز کار دشواری نخواهد بود اما در عین حال توجه داشته باشیم که اگر Lookup Table، که نقطهی شروع کوئری است، به هر دلیلی با مشکل مواجه گردد، کل اپلیکیشن یا حداقل بخشهای بسیاری از آن از کار خواهند افتاد!
sharding-19c-new-features
از مهمترین قابلیت های sharding در Oracle 19c میتوان به موارد زیر اشاره کرد:
MULTIPLE SHARDS IN A SINGLE MULTITENANT DATABASE
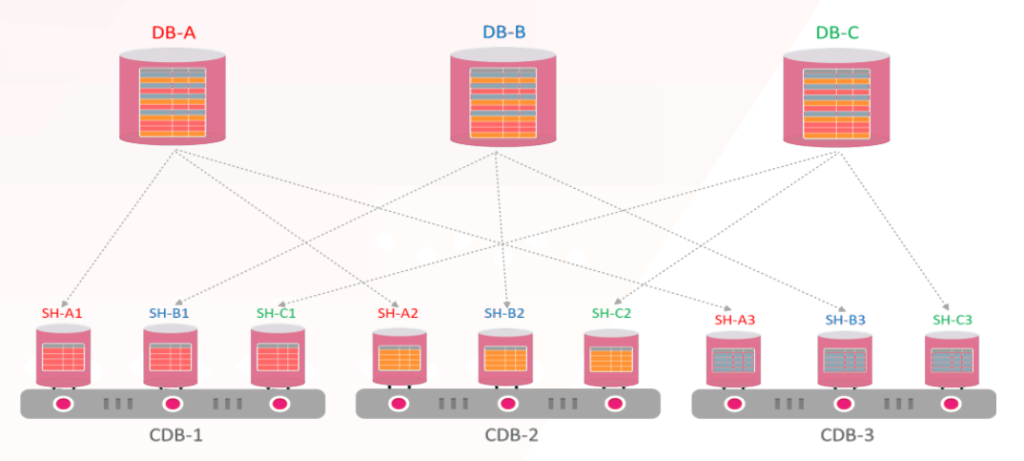
در oracle 19c امکان ادغام sharded database فراهم شده است. یعنی مثلا فرض کنیم سه دیتابیس DB-A,DB-B,DB-C را هر کدام شامل 3 shard میباشند. میتوان هرکدام از این شاردها را به عنوان یک PDB در نظر گرفت که به آنها PDB- Shards میگویند.
در اوراکل 19 میتوان با استفاده از CDB میزبان PDBهای مختلف از دیتابیسهای مختلف بود. در این صورت با استفاده و سود بردن از قابلیتهای CDBها میتوان به کارایی دیتابیسها نیز افزود :
SCALABLE CROSS SHARD QUERY COORDINATORS
از دیگر ویژگیهای sharding در اوراکل 19 میتوان به مبحث SCALABLE CROSS SHARD QUERY COORDINATORS اشاره کرد.
یعنی برای استفاده از شاردینگ میتوان از Shard Catalog استفاده کرد و میتوان از آن به عنوان هماهنگ کننده shard queryها استفاده کرد و همچنین برای این Shard Catalog یک یا چند سرور را به عنوان Active Data Guard standby databases در نظر گرفت:
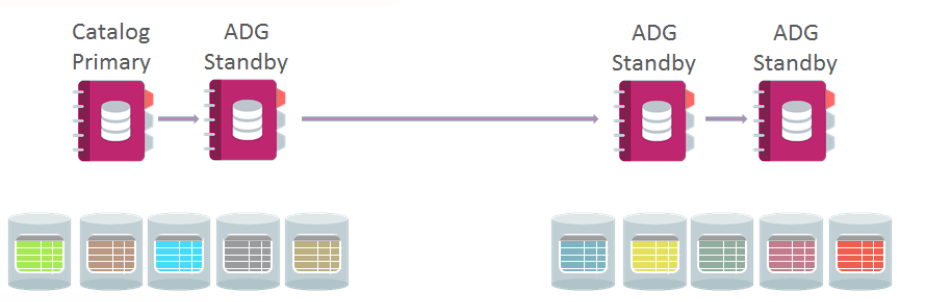
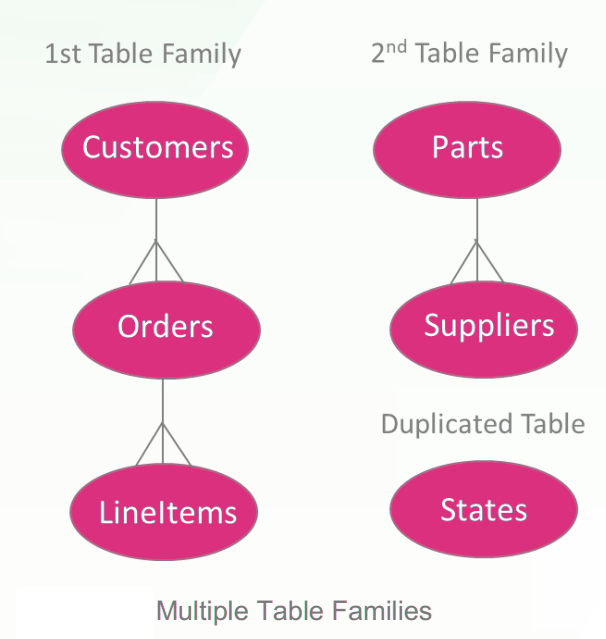
MULTIPLE TABLE FAMILIES
همانطور که در قسمت معماری sharding هم بیان شد، یک Shard Database میتواند از ادغام جداول و یا قسمت های مختلف از جداول مختلف استفاده کند.
نتیجه گیری:
استفاده بجا از Sharding و همچنین انتخاب صحیح و درست از انواع معماریهای آن بنا به کارایی که از دیتابیسهامون انتظار داریم به خصوص در Oracle 19c که قابلیتهای بیشتری نسبت به Oracle 12 دارد، قطعا باعث کارایی بیشتر سیستم ما خواهد شد.