راهکارهای مقاومپذیری در برابر بروز بحران

سازمان ها جهت حفظ سلامت دیتا و همچنین دسترس پذیری بیشتر در بستر فن اوری اطلاعات، از مکانیزمهای مختلفی بصورت همزمان میبایست استفاده کنند.
در این نوشتار ابتدا مفاهیم اولیه مربوط به مقاوم پذیری در برابر خطا را در بستر فن آوری اطلاعات تشریح میکنیم و سپس قدم های رسیدن به یک بستر مقاوم پذیر در برابر خطا را توضیح می دهیم.
فاکتورهای RPOو RTO
در مقوله مقاوم پذیری در برابر خطای دیتا، دو فاکتور اهمیت بسیار زیادی دارند
(RTO( Recovery Time Objective: مشخص میکند از زمان بروز حادثه، چند دقیقه اختلال در سرویس دهی را میتوانید تحمل کنید. به عنوان مثال اگر فرایند بازیابی اطلاعات شما از دستگاه Backupسه ساعت به طول بینجامد به این معنی است که در صورتی که نیاز به بازیابی از Backupپیدا کنید ممکن است 3 ساعت قطعی سرویس را تجربه کنید.این فاکتور نیز بر حسب دقیقه اندازه گیری می شود.
برای کاهش زمان RPOنیازمند استفاده از مکانیزمهای مختلفی در حوزه دیتا هستید. مکانیزمهایی مانند Reolication, Backup, Snapshotبه شما کمک میکنند RPOرا کاهش دهید. مقوله RTOعلاوه بر فاکتورهای RPOمیبایست در لایه های مختلف مرکز داده افزونگی را افزایش دهید. به عنوان مثال هم در فیزیک مرکز داده، هم در شبکه و هم در لایه پردازشی مرکز داده، مکانیزمهای متعددی پیاده سازی کنید که RTOرا کاهش دهد.
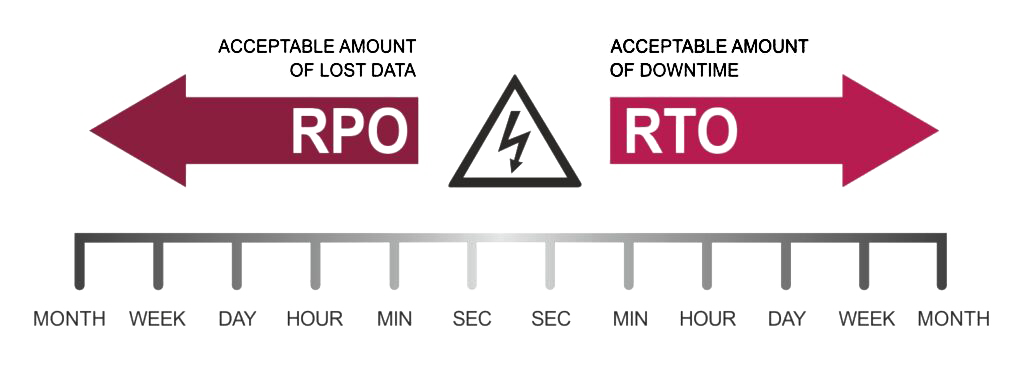
(RPO( Recovery point Objective: این فاکتور که بر حسب دقیقه اندازه گیری می شود مشخص می کند در صورت بروز بححران اساسی برای دیتا، سازمان میخواهد به چند دقیقه قبل از ساعت بروز حادثه برگردد؟ به عنوان مثال در صورت خرابی دیتا، آیا اگر دیتای 60 دقیقه آخر را نداشته باشید قابل پذیرش است؟ هر جقدر RPOکمتر باشد، هم روشش های حفط سلامت دیتا متعدد تر و پیچیده تر می شود و هم هزینه سازمان بالاتر می رود. به عنوان مثال در یک بانک ممکن است نتوئانید حتی یک دقیقه از دست رفتن دیتا را هم بپذیرید.
مفاهیم Uptime و SLA
فاکتورهای دیگری به نام Uptimeیا SLA(Service Level Agreement) در مراکز داده مطرح است
Uptime: منظور از Uptimeاین است که خدمات مرکز داده در طول یک بازه زمانی (معمولن یکسال) چند درصد با میفیت مناسب ارایه میگردد. به عنوان مثال مرکز داده ای که ادعا می کند Uptimeبرابر یا 99.99% دارد به این معنی است که در سال، کمتر از 52:35(52 دقیقه و 35 ثاتنیه) دچار اختلال می شود.

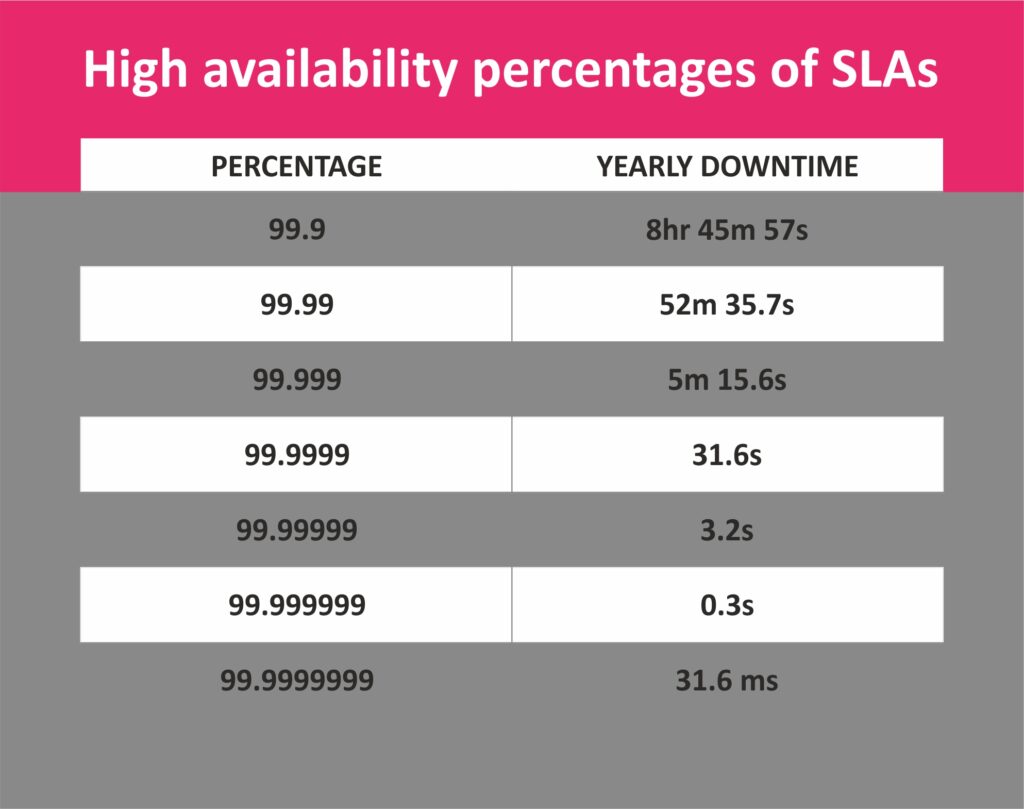
(SLA(Service Level Agreement: منظور از SLA همان مفهوم Uptimeاست که تحت یک قرارداد یا قرار رسمی بین دو یا چند طرف توافق می شود. بعنوان مثال ممکن است از یک مرکز داده سرویس بگیرید و داخل قرارداد ذکر کنید که SAL خدمات، 99.999% است. و این به این معنی است که سرویس دهنده متعهد است در سال میبایست کمتر از 5:15 (5 دقیقه و 15 ثانیه) دچار اختلال گردد.
هر مرکز داده، حوزه مسولیت خود و همچنین آیتم هایی که داخل یا بیرون از SLAتوافقی قرار دارد در سند SLAذکر میکند. بعنوان مثال ممکن است در یک قرارداد، SALبرابر با 99.9% توافق شود و از طرفی، وقوع حوادث فیزیکی مانند سیل و زلزله، از تعهدات سرویس دهنده خارج محسوب گردد. در این حالت؛ سرویس دهنده مجبور نخواهد بود در دو مرکز داده که از جهت فیزیکی فاصله بیش از 100 کیلومتر دارند به شما سرویس دهی نماید.
برخی از قرارداد های SLAمرکز داده، تنها به قطعی و وصلی خدمت مربوطه اشاره میکنند و برخی دیگر، علاوه بر قطعی و وصلی، بر برخی پارامترهای کیفی مانند Response Time یا میزان پهنای باند ارتباطی نیز در لایه های مختلف اشاره می نمایند.
در صورتی که بخواهید مرکز داده ای شامل SLA یا Uptime مشخص طراحی کنید میبایست حوزه های مربوط به SLAرا مشخص نمایید. چرا که افزودن برخی موارد به تعهدات SLAمی تواند هزینه شما را به میزان قابل ملاحظه ای افزایش دهد. به عنوان مثال همینکه بلایای طبیعی جزو مواردی باشد که میبایست پوشش داده شود یا خیر، ممکن است شما را به دو یا چند مرکز داده نیازمند کند و به همین ترتیب هزینه های شما را بصورت نمایی افزایش دهد
قدم های ایجاد بستر مقاوم پذیر در برابر بحران
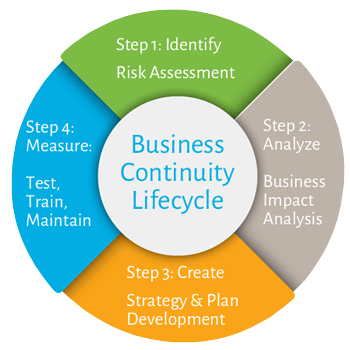
مقولات Business Continuity و Disaster Recovery مقولات نزدیک به هم هستند.Business Continuity مجموعه ای از برنامه ها، فرایند ها، سیاست ها و اجراییات و پایش ها است که چه در شرایط بحران و چه غیر بحران، در راستای تداوم کسب و کار به کار گرفته می شود و در حقیقت Disaster Recovery یک زیرمجموعه از Business Continuity است که در هنگام بروز بحران، کسب و کار را به سلامت حفظ می کند.مراحل کلی جهت اجرای بستری جهت افزایش مقاوم پذیری در برابر بحران به نگاهی به Business Continuity در حوزه فن اوری اطلاعات، به قرار ذیل هستند

قدم اول: شناخت وضعیت، تهیه Service Catalogue
در قدم ابتدایی میبایست شناخت وضعیت موجود از جهت بستر و سامانه های کسب و کار مورد شناخت قرار گیرد. در این مرحله سامانه هایی که بطور مستقیم با کسب و کار اصلی سازمان در ارتباط هستند میبایست در اولویت و اهمیت مجزایی بررسی گردند. در حقیقت در انتهای این فاز، لیستی شامل سرویس های الکترونیکی مهم سازمان و اطلاعات کلی در مورد هر کدام مانند شخص مسول سامانه و همچنین یک سری اطلاعات کلی فنی در مورد سرویسها، در دست خواهید داشت. در مجموعه بهروش ITIL به این مقوله Service Catalogueگفته می شود و مشخصات این مستند در ITIL ذکر شده است.
در قدم ابتدایی میبایست شناخت وضعیت موجود از جهت بستر و سامانه های کسب و کار مورد شناخت قرار گیرد. در این مرحله سامانه هایی که بطور مستقیم با کسب و کار اصلی سازمان در ارتباط هستند میبایست در اولویت و اهمیت مجزایی بررسی گردند. در حقیقت در انتهای این فاز، لیستی شامل سرویس های الکترونیکی مهم سازمان و اطلاعات کلی در مورد هر کدام مانند شخص مسول سامانه و همچنین یک سری اطلاعات کلی فنی در مورد سرویسها، در دست خواهید داشت. در مجموعه بهروش ITIL به این مقوله Service Catalogueگفته می شود و مشخصات این مستند در ITIL ذکر شده است.
قدم دوم: آنالیز و تهیه BIA
در این مرحله، سناریو های مهمی که باعث ایجاد ضرر و زیان در کسب و کار می شوند (در حوزه فن آوری اطلاعات) و همچنین میزان تبعات احتمالی آن شناسایی و تحلیل می شوند. به این ترتیب مشخص می شود دیتاها و خدمات الکترونیکی تا چه میزان برای سازمان ارزش سرمایه گذاری دارند. به عنوان مثال در یک بانک، در صورت از دست رفتن حتی چند دقیقه دیتای سامانه Core Banking، ضرر و زیان بسیار زیادی به سازمان وارد می شود لذا میزان سرمایه گذاری جهت پایین اوردن RPOو RTOبسیار بیشتر از یک سازمان معمولی است. ممکن است برخی سامانه ها در همان بانک، اثر کمی در ایجاد ضرر و زیان به سازمان داشته باشند. به این ترتیب این امکان فراهم می شود که سرویسها و حدمات مرکز داده را به سطوح مختلف اولویتی از زاویه نگاه اهمیت حفظ دیتا و سرویس تقسیم کنید. یکی از فعالیت های مهم در این مرحله این است که ورودی ها و وابستگی های هر سرویس را نیز مشخص کنید. ممکن است یک سامانه برای خدمت دهی نیازمند چند سامانه یا سرویس جنبی باشد. با تهیه Service Dependency Model در حقیقت ارتباطی عمودی بین هر سامانه با خدمات پایه ای مرکز داده (لایه های مختلف مرکز داده)برقرار میکنید و هم به صورت افقی ارتباط و وابستگی های بین سامانه های مختلف مشخص میگردد.
در مجموعه بهروش ITIL توصیه هایی برای تدوین Service Dependency Modelوجود دارد. برای تدوین یک BIA با محوریت فن آوری اطلاعات، حوزه های ذیل مهم هستند


فعالیت های مهم کسب و کار که از بستر فن آوری اطلاعات استفاده میکنند. به عنوان مثال برای یک شرکت بیمه، تمامی فعالیت هایی که برای گردش کسب و کار انجام می شوند معمولن توسط مجموعه سامانه های Core Insuranceو پورتال سازمانی انجام می شوند. لذا کلیه سامانه های مربوطه میبایست در BIAتحلیل شوند و میزان خسارت سازمان در صورت بروز خادثه برای هر کدام از سامانه های وابسته مشخص گردد. از روی میزان خسارت میتوان میزان RPOو RTOرا مشخص کرد

لیست سامانه های کسب و کار بهمراه شدت اثر و اهمیت بروز بحران روی هر کدام: لیست تمامی سامانه هایی که به کسب و کار سازمان مربوط می شوند بهمراه میزان اثر گذاری آنها در کسب درامد و میزان ضرر و زیان سازمان در صورت بروز اتفاق برای آن سامانه ها

لیست سامانه های عمومی بهمراه شدت اثر و اهمیت بروز بحران روی هر کدام: لیست تمام سامانه هایی که سرویس ها و خدمات جنبی در سازمان ارایه میکنند ولی اثر مستقیم در درامد سازمان ندارند، بهمراه میزان و شدت خسارت سازمان بصورت مستقیم یا غیر مستقیم در صورت بروز اتفاق برای هر کدام از سامانه ها. به عنوان مثال معمولن سامانه بستر پست الکترونیکی سازمان، اثر مستقیم در کسب و کار سازمان ندارد ولی در صورت بروز اتفاق چون گردش کاری برخی سازمانها از طریق ایمیل انجام می شود، ممکن است در کیفیت کارکرد پرسنل یا نمایندگان سازمان اثر داشته باشد. بر اساس میزان اثر، ممکن است RPO/RTO متفاوتی برای اینگونه ابزارها و نرم افزارها لحاظ گردد

فرایند های مهم سازمانی: یکی از نگاه های دیگری که میتوانید داشته باشید، بررسی فرایند های مهم سازمانی و سامانه های مربوط به آن است.

ذینفعان هر سامانه و گستره اثر گذاری بحران احتمالی: برای هر کدام از موارد بالا، بازه استفاده کنندگان از خدمات میبایست مشخص باشد. همچنین مشخص شود اختلال در سرویس مربوطه، روی چه ذینفعانی اثر می گذارد و میزان اثر گذاری و ضرر زیان احتمالی مستقیم یا غیر مستقیم آن هم مشخص شود.
همچنین دسته بندی خدمات الکترونیکی در مراکز داده بزرگ و متوسط می تواند راهکار خوبی جهت بهینه سازی کیفیت- قیمت باشد. به این ترتیب که میتوانید کلیه سامانه ها و دیتاهای مربوطه را به چند سطح مختلف تقسیم بندی کنید (بعنوان مثال سطوح A، B، C، D) و برای هر سطح، میزان RPO,RTO مختلف تدوین نمایید و به تبع، راهکار فنی طراحی شده برای هر سطح هم میتواتند متفاوت باشد. به این ترتیب یک بالانس بین کیفیت و هزینه ایجاد می گردد.

قدم سوم: طراحی
در این مرحله بر اساس شناخت صورت گرفته، و سیاست های مشخص شده،طراحی فنی بستر مورد نیاز انجام می شود. برای تامین RPO,RTO مو.رد نیاز در هر کدام از سطوح دسترس پذیری دسته بندی شده (Aتا (D در هر لایه از لایه های مختلف مرکز داده، مکانیزمها و روش های مختلفی وجود دارد که به فراخور قابل استفاده هستند. از جمله می توان به موارد زیر اشاره نمود:
استفاده از بیش از یک مرکز داده: در صورتی که سیاست سازمان این است که نسبت به بلایای طبیعی و یا حتی اتفاقاتی مانند قطعی برق مقاومت داشته باشد میبایست بیش از یک مرکز داده داشته باشید و این امکان را فراهم سازید که در صورت بروز بحران برای هر کدام از مراکز داده، در مرکز داده دوم یا سوم بسرعت بتوانید خدمت رسانی را ادامه دهید
استفاده از استانداردهای سطوح بالاتر در طراحی زیرساخت فیزیکی مرکز داده: طبق استاندارد TIA-942، چهار سطح به عنوان سطوح کیفی شرایط فیزیکی مرکز داده مشخص شده است. هر کدام از این 4 سطح میبایست در طراحی مرکز داده از یک سری امکانات و تعدادی راهکارهای افزایش مقاومت در برابر اتفاقات بهره جست. سطح 4 نسبت به سطح 1، از امکانات و مکانیزمهای مقاوم پذیری در برابر خطای بیشتری استفاده می کند.در صورتی که سطوح بالایی از دسترس پذیری مورد نیاز است میبایست از سطوح بالاتری از استاندارد استفاده کنید. همچنین در زمینه فرایند های راهبری و تعمیرات نگهداری زیرساخت فیزیکی مرکز داده حساسیت بیشتری به خرج دهید
استفاده از ارتباطات شبکه افزونه در شبکه دسترسی کاربران: هر مرکز داده میبایست به دنیای بیرونی خود ارتباط شبکه ای داشته باشد . انواع مختلف ارتباطات شبکه را هم در داخل و هم بیرون مرکز داده مشخص کنید و بسته به نیاز در هر کدام افزونگی را رعایت کنید
استفاده از تجهیزات افزونه در لایه های مختلف: در دسته بندی نوین، زیرساخت اکتیو مرکز داده به سه لایه مختلف تقسیم بندی میشود. لایه ذخیره سازی، لایه پردازشی و لایه شبکه. در هر کدام از لایه ها میبایست از افزونگی در زمینه تجهیزات استفاده نمایید
استفاده از تکنولوژی های Fault Recovery نرم افزاری مناسب: تنها استفاده از تجهیزات افزونه شما را در برابر اتفاقات محفوظ نمیکند. بلکه میبایست مکانیزمهای هوشمند نرم افزاری مناسب داشته باشید که از این بستر و ظرفیت بصورت بهینه بتوانید استفاده کنید. در هر لایه از سه لایه نامبرده در مرکز داده، تکنولوژی ها و مکانیزمهای نرم افزاری بسیاری برای مقاوم پذیری در برابر خطا وجود دارد. بعنوان مثال در لایه پردازشی مرکزداده، در یک مرکز داده که از راهکار مجازی سازی شرکت VMware استفاده میکند میتوانید از مکانیزم هایی مانند Vsphere Clusteringو SRM بعنوان راهکارهای نرم افزاری به عنوان مکمل افزونگی سخت افزاری تجهیزات، بهره بجویید. یا اگر از پایگاه داده Oracle DBاستفاده میکنید، از مکانیزمهای High Availabilityپیشنهادی این شرکت به فراخور استفاده نمایید
استفاده از فرایند ها، سیاست ها و نیروی انسانی مناسب: بسیاری از اتفاقات ممکن است قبل از وقوع قابل پیش بینی باشند. بهره جویی از فرایند های دقیق و کامل، سیاست های جامع و نیروی انسانی خبره و دقیق می تواند علاوه بر جلوگیری از بسیاری از اتفاقات، در زمان بروز بحران به شما کمک کند به سرعت شرایط با ره حالت عادی برگردانید
مستند سازی دقیق و به روز: در مراکز داده متوسط و بزرگ، تجهیزات و اجزای زیادی استفاده می شود. مستند سازی دقیق مرکز داده، موجب می شود در زمان بروز بحران، بتوانید به سرعت اکشن مورد نیاز را بگیرید. مقوله به روز رسانی مستندات مقوله حساسی است که متاسفانه در بسیاری از مراکز داده مغفول می شود.
قدم چهارم: پایش و تست

استفاده از بستر پایش هوشمند: یکی از مسایل بسیار مهم در زمان بروز بحران، خبر دار شدن کارشناسان و مدیران از بروز و مشخصات بحران است. لذا استفاده از ابزارهای مناسبی که بتواند به شما کمک کند در سریعترین زمان، بروز بخران را مطلع شوید و هر چه سریعتر از مشخصات جزیی بحران اطلاع یابید به شما کمک میکند در کمترین زمان مشکل مربوطه را حل کنید. علاوه بر آن، استفاده بهینه از یک بستر پایش می تواند بسیاری از بحران ها را قبل از وقوع پیش بینی کند و از بروز آن جلوگیری نماید. به عنوان مثال در تجهیزات ذخیره سازی اطلاعات، بسیاری از خرابی دیسک ها بصورت پیش بینی شونده توسط دستگاه گزارش می شود و آلارم داده می شود که عمر مفید فلان دیسک در حال اتمام است. در صورتی که بستر پایش خوبی داشته باشید و فرایند های دقیقی برای پیگیری اینگونه موارد اجرا کنید میتوانید قبل از خرابی ، دیسک را تعویض کنید.
اجرای مانور های برطرف سازی بحران: در زمان بروز بحران نیروی انسانی شما میبایست امادگی ذهنی لازم برای برخورد سری و دقیق به دور از استرس داشته باشد و جهت پرهیز از خطای انسانی، و اثر گذاری استرس ناشی از اختلال، انجام مانور بسیار حایز اهمیت است
برای Planned Downtimeو Unplanned Downtime بصورت مجزا برنامه داشته باشید. یک مرکز داده در طول دوران حیات خود گهگاه نیازمند Planned Downtimeدر لایه های مختلف خواهد بود. ممکن است برای عملیات Periodic Maintenanceنیازمند این شوید که بخشی از اجزای مرکز داده را بطور موقت خاموش کنید. به عنوان مثال اکثر سیستم عامل ها بعد از به روز رسانی نیازمند ریبوت هستند و چند دقیقه از دسترس خارج می شوند.
برای سناریو های مهم بروز بحران، حتمن برنامه مدون و تست شده برای بازگشت به شرایط عادی تدوین کنید. در شرایط بروز بحران، اگر راهکاری در دست داشته باشید که قبلن مراحل آن به دقت طراحی شده و تست شده ، هم در زمان کمتری می توانید شرایط را به حالت عادی در بیاورید و هم امکان بروز خطای انسانی در فرایند بازیابی بشدت کاهش می یابد.
بطور منظم مانور بروز بحران برگزار کنید: برای هر کدام از سطوح اهمیت (A,B,C,D) طبق برنامه مدون، مانور بروز بحران اجرا کنید و تجربیات را مستند نمایید.